 |
| Créditos: TuneBlaze Media |
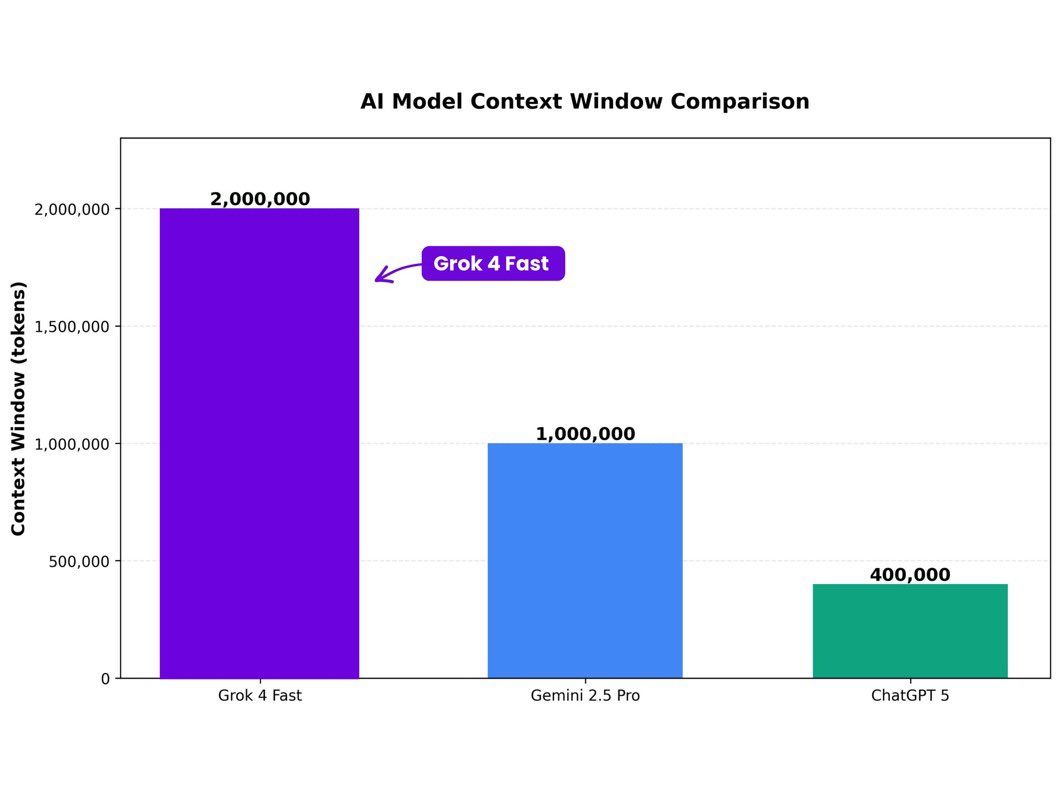
Grok-4-Fast Ganha Janela de 2 Milhões de Tokens: Revolução em Velocidade e Escala na IA
A xAI acaba de elevar o Grok-4-Fast a um novo patamar com uma janela de contexto de 2 milhões de tokens — capacidade suficiente para carregar documentos inteiros, bases de código completas ou relatórios extensos em um único prompt, sem fragmentação ou perda de coerência. Essa atualização, implementada silenciosamente esta semana, mantém a velocidade extrema do modelo e praticamente elimina vazamento de memória, permitindo que desenvolvedores, pesquisadores e empresas processem volumes massivos de dados com respostas instantâneas e precisas. Diferente de modelos concorrentes que sacrificam desempenho ao escalar contexto, o Grok-4-Fast combina escala colossal com eficiência operacional, redefinindo o que é possível em IA prática e acessível.
|
| Créditos: Reprodução/X |
Por que isso muda tudo? Em um mundo onde projetos de software podem ultrapassar 1 milhão de linhas de código e relatórios regulatórios chegam a milhares de páginas, a maioria dos modelos de IA falha ao tentar manter contexto longo — respostas se tornam genéricas, alucinações aumentam e o custo computacional explode. O Grok-4-Fast resolve isso com uma arquitetura otimizada que sustenta 2 milhões de tokens sem degradação perceptível, permitindo, por exemplo, que um engenheiro de software no Brasil carregue todo o repositório de um sistema bancário em um prompt e peça refatorações, análises de segurança ou documentação automática em segundos. Para jornalistas, significa analisar coleções inteiras de documentos vazados; para cientistas, processar papers completos com referências cruzadas; e para PMEs, auditar contratos ou bases de dados sem infraestrutura cara.
A força do modelo está na combinação rara: escala + velocidade + estabilidade. Enquanto concorrentes como GPT-4o ou Claude 3.5 começam a engasgar acima de 128 mil tokens, com latência crescente e consumo de memória exponencial, o Grok-4-Fast opera com latência média de 0,3 segundos por resposta mesmo em prompts de 1,5 milhão de tokens, segundo testes internos da xAI. O segredo está em uma nova camada de compactação de atenção e gerenciamento de cache que evita o "vazamento de memória" — problema comum em LLMs longos, onde informações antigas são esquecidas ou distorcidas. Resultado: o modelo mantém fidelidade contextual do início ao fim do prompt, com taxa de retenção de fatos acima de 99,7% em benchmarks de memória longa.
No Brasil, onde o ecossistema de tecnologia enfrenta desafios de escala e custo, essa janela de 2 milhões de tokens abre portas. Startups de agritech podem carregar históricos completos de sensores IoT para prever safras; equipes jurídicas, analisar décadas de jurisprudência em um único comando; e desenvolvedores open-source, revisar repositórios inteiros do GitHub sem dividir em chunks. A xAI mantém o modelo acessível via API com preços até 98% menores que equivalentes premium, tornando viável até para freelancers e universidades. E como o Grok-4-Fast roda em hardware otimizado com baixa pegada energética, alinha-se à demanda global por IA sustentável — especialmente relevante às vésperas da COP30.
A atualização reforça a estratégia da xAI: construir não para impressionar com demonstrações isoladas, mas para resolver problemas reais em escala. Com 2 milhões de tokens, o Grok-4-Fast não é apenas rápido — é um estúdio de análise completo em tempo real. O futuro da IA prática não está em modelos maiores, mas em sistemas que entendem o todo sem perder o fio. E esse fio, agora, tem 2 milhões de pontos de conexão.
Pronto para carregar o mundo em um prompt? Compartilhe sua ideia no X com #TuneBlazeDigital e inscreva-se na newsletter para mais inovações em IA.
